O bug da CrowdStrike: O dia em que a terra parou e impactou a Microsoft
Fala galera! Seis tão baum?
Na última sexta-feira, dia 18 de julho, um grande apagão cibernético tomou conta de milhões de computadores ao redor do mundo, causando transtornos em aeroportos, bancos e diversos outros setores essenciais. A causa deste problema foi um bug no sistema de controle de qualidade da CrowdStrike, afetando cerca de 8,5 milhões de dispositivos rodando Windows.
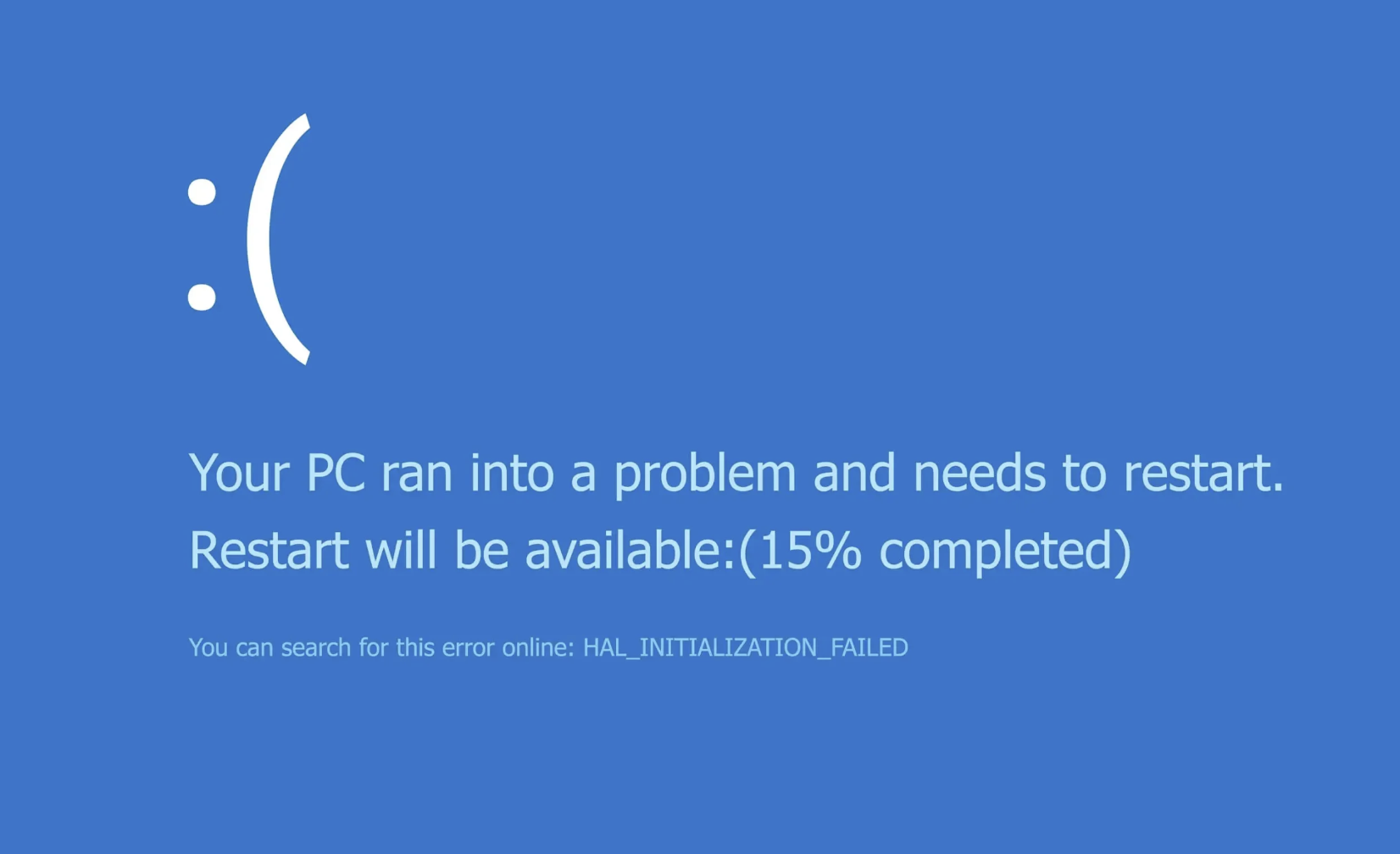
O que aconteceu?
A CrowdStrike, uma das líderes no mercado de segurança cibernética, lançou uma atualização problemática que não deveria ter chegado aos sistemas finais. Devido a um bug no “Content Validator” (etapa de verificação de qualidade da CrowdStrike), duas instâncias adicionais foram entregues aos dispositivos, mesmo contendo dados problemáticos.
A atualização problemática da CrowdStrike incluía um “Channel File 291” que causava uma leitura de memória fora do alcance quando processado pelo aplicativo Falcon. Esta leitura resultava em uma exceção, um erro crítico que o sistema não conseguia contornar, levando ao travamento do Windows e à exibição da famosa Tela Azul da Morte (BSOD).
Quem é a CrowdStrike e o que é o CrowdStrike Falcon?
A CrowdStrike é uma empresa renomada no campo de segurança cibernética, especializada em fornecer soluções avançadas para a proteção de endpoints. Seu principal produto, o CrowdStrike Falcon, é uma plataforma de segurança corporativa projetada para proteger dispositivos contra uma vasta gama de ameaças cibernéticas.
O CrowdStrike Falcon combina antivírus de próxima geração com capacidades de monitoramento de ameaças e detecção e resposta em endpoints (EDR). Utilizando inteligência artificial e machine learning, o Falcon é capaz de detectar e neutralizar ameaças em tempo real, oferecendo uma defesa robusta contra ataques cibernéticos e garantindo a integridade e a segurança dos sistemas protegidos.
Impacto Global
O bug na atualização da CrowdStrike teve um impacto massivo, causando a paralisação de serviços em aeroportos, bancos e outras infraestruturas críticas ao redor do mundo. A falha resultou em interrupções significativas, com muitos sistemas essenciais ficando offline e inoperantes.

Quem foi o culpado?
Inicialmente, muitos atribuíram o incidente à Microsoft, dada a prevalência da Tela Azul da Morte (BSOD) nos sistemas Windows afetados. No entanto, investigações posteriores revelaram que o verdadeiro culpado era um bug no processo de controle de qualidade da CrowdStrike. A empresa admitiu o erro e detalhou como a atualização problemática foi entregue aos dispositivos finais.

O CEO da CrowdStrike, George Kurtz, emitiu um pedido de desculpas público. Em uma declaração transmitida no programa “Today” da NBC News, Kurtz expressou seu arrependimento pelo impacto negativo causado a clientes, viajantes e outros afetados pela falha no sistema.
Kurtz afirmou: “Lamentamos profundamente o transtorno causado aos nossos clientes e a todos os que foram impactados, incluindo nossa própria empresa.” Ele assegurou que a recuperação estava em andamento e que muitos clientes já estavam reinicializando seus sistemas. Embora a maioria dos sistemas deva retornar ao funcionamento normal, ele alertou que alguns poderão enfrentar atrasos na recuperação automática.
O CEO garantiu que a CrowdStrike está comprometida em fornecer suporte completo até a recuperação total de todos os clientes afetados e que a empresa está trabalhando para implementar medidas que evitem futuros incidentes semelhantes.
Como resolver o problema?
Para resolver o problema em máquinas físicas e virtuais no Microsoft Azure, a CrowdStrike e a Microsoft recomendaram as seguintes ações:
Para hosts físicos:
- Inicialize o Windows no Modo Seguro ou no Ambiente de Recuperação do Windows.
- Navegue até o diretório C:\Windows\System32\drivers\CrowdStrike.
- Localize o arquivo correspondente a “C-00000291*.sys” e exclua-o.
- Inicialize o host normalmente.
Observação: Hosts criptografados com BitLocker podem precisar de uma chave de recuperação.
Para ambientes em nuvem pública, incluindo máquinas virtuais:
- Desconecte o volume do disco do sistema operacional do servidor virtual afetado.
- Crie um snapshot ou backup do volume do disco antes de prosseguir, como precaução contra alterações indesejadas.
- Anexe/montar o volume a um novo servidor virtual.
- Navegue até o diretório %WINDIR%\System32\drivers\CrowdStrike.
- Localize o arquivo correspondente a “C-00000291*.sys” e exclua-o.
- Desconecte o volume do novo servidor virtual.
- Reanexe o volume corrigido ao servidor virtual afetado.
Links que podem ajudar na solução do problema:
- Recovery Tool da Microsoft: New Recovery Tool to help with CrowdStrike issue impacting Windows endpoints
- Recovery para VMs no Azure: Recovery options for Azure Virtual Machines (VM) affected by CrowdStrike Falcon agent
- Comunicado Oficial da Cloudstrike: Remediation and Guidance Hub: Falcon content update for Windows
- Post da AWS: How do I recover AWS resources that were affected by the CrowdStrike Falcon agent?
Lições aprendidas
Este incidente traz importantes lições sobre segurança, testes e homologações, processos de atualização de ambientes e dependência da tecnologia:
- Segurança: A necessidade de robustos processos de controle de qualidade para evitar que atualizações problemáticas alcancem os sistemas finais.
- Testes e Homologações: Importância de realizar testes exaustivos em ambientes controlados antes de lançar atualizações em larga escala.
- Processos de Atualização: A implementação de etapas adicionais de verificação pode prevenir a disseminação de atualizações defeituosas.
- Dependência da Tecnologia: A importância de ter planos de contingência e mecanismos de recuperação para mitigar os impactos de falhas tecnológicas em sistemas críticos.
O incidente com a CrowdStrike serve como um lembrete poderoso da responsabilidade que nós, profissionais de tecnologia, carregamos. O mundo moderno depende profundamente do nosso trabalho, e pequenos erros podem ter consequências significativas e de longo alcance. Não podemos simplesmente rir dos incidentes que afetam nossos colegas, pois todos nós estamos constantemente lançando software em produção, e um descuido pode acontecer com qualquer um de nós.
Este evento sublinha a importância de estarmos sempre atualizados e comprometidos com o aprendizado contínuo sobre segurança, processos e qualidade de entrega de software. A rápida evolução das tecnologias e das ameaças exige que nunca paremos de estudar e nos aprimorar.
Além disso, processos robustos de validação, testes e homologação são essenciais no portfólio de um profissional de DevOps. Eles não são apenas práticas recomendadas, mas sim uma necessidade crítica para garantir que o software entregue seja seguro, confiável e funcional.
Se você tiver alguma dúvida ou comentário, sinta-se à vontade para compartilhá-los conosco na seção de comentários abaixo!
É isso galera, espero que gostem!
Forte Abraço!